ChatGPT Images 2.0 : le guide complet pour bien démarrer
ChatGPT Images 2.0 n’est pas seulement un générateur d’images plus joli que le précédent. C’est un outil de production visuelle intégré à ChatGPT : il comprend une intention, planifie une composition, peut améliorer son résultat avant génération avec les modèles de réflexion, accepte des formats flexibles, édite des images existantes, et produit enfin du texte lisible dans les visuels. Ce premier guide pose les fondations : comprendre les modes, choisir le bon format, écrire un premier prompt utile, itérer sans repartir de zéro, et sortir un visuel réellement exploitable.
Vous ouvrez ChatGPT, vous tapez « crée une belle image pour LinkedIn », vous attendez quelques secondes, et vous obtenez un visuel correct. Pas mauvais. Pas inutilisable. Mais pas vraiment publiable non plus. Le texte est trop vague, le cadrage ne correspond pas au canal, le style manque d’intention, et l’image ressemble encore à un test d’IA plutôt qu’à un asset de communication.
C’est exactement là que se joue la différence entre un utilisateur occasionnel et quelqu’un qui maîtrise vraiment ChatGPT Images 2.0. Le modèle est devenu beaucoup plus puissant, mais il ne remplace pas votre direction artistique. Il l’exécute. Plus vous êtes clair sur la scène, le format, le style, le texte, l’usage final et les contraintes, plus le résultat se rapproche d’un visuel professionnel.
Cet article est le premier d’une série complète. L’objectif : vous emmener de zéro — ou de « je génère des images de temps en temps » — à un workflow structuré pour créer des affiches, miniatures, visuels marketing, infographies, séries cohérentes, retouches, assets multi-formats et pipelines automatisées via l’API.
ChatGPT Images 2.0 : ce qui change vraiment
ChatGPT Images 2.0 a été annoncé par OpenAI le 21 avril 2026. La promesse officielle tient en trois idées : meilleur rendu du texte, meilleure prise en charge multilingue, et contrôle plus fin des styles, des compositions et des formats. OpenAI le présente aussi comme un modèle capable de produire des visuels plus riches : affiches, BD, infographies, maquettes, pages éditoriales, supports pédagogiques, scènes photoréalistes ou compositions très denses.
La rupture ne vient donc pas seulement de la qualité esthétique. Elle vient de l’intégration dans ChatGPT. Vous ne travaillez plus avec un générateur séparé où chaque prompt est un lancer de dés. Vous pouvez dialoguer, corriger, préciser, demander une variante, changer le ratio, modifier une zone, ajouter un titre, simplifier la composition, ou repartir d’une image existante.
OpenAI a aussi introduit les images avec réflexion. Quand le modèle dispose de plus de temps pour réfléchir, il peut planifier et affiner le résultat avant de générer l’image. En pratique, cela change beaucoup les demandes complexes : affiches avec texte, layouts denses, scènes à plusieurs éléments, infographies, visuels de marque, ou images qui doivent respecter une hiérarchie précise.
Autre signal important : côté API, les snapshots dall-e-2 et dall-e-3 sont retirés le 12 mai 2026. Il ne faut pas comprendre cela comme « DALL·E disparaît de ChatGPT » : il s’agit d’abord d’une dépréciation API, avec remplacement recommandé par gpt-image-1 ou gpt-image-1-mini. Mais le message est clair : la génération d’images chez OpenAI bascule désormais vers la famille GPT Image.
Le signal externe est également fort : dès sa sortie, Image Arena a annoncé GPT-Image-2 en première position, avec un écart record de +242 points en Text-to-Image. Ce n’est pas une garantie que le modèle gagne sur tous les usages. C’est en revanche un bon indicateur : le saut de qualité est suffisamment net pour être visible dans les comparaisons publiques.
Ne le voyez pas comme « Midjourney dans ChatGPT ». Voyez-le comme un assistant de production visuelle. Vous lui donnez un brief. Il propose une image. Vous la corrigez comme vous corrigeriez un designer junior : plus sombre, moins chargé, format vertical, texte plus grand, produit plus centré, fond plus premium, meilleure lisibilité mobile. C’est cette boucle qui fait la puissance de l’outil.
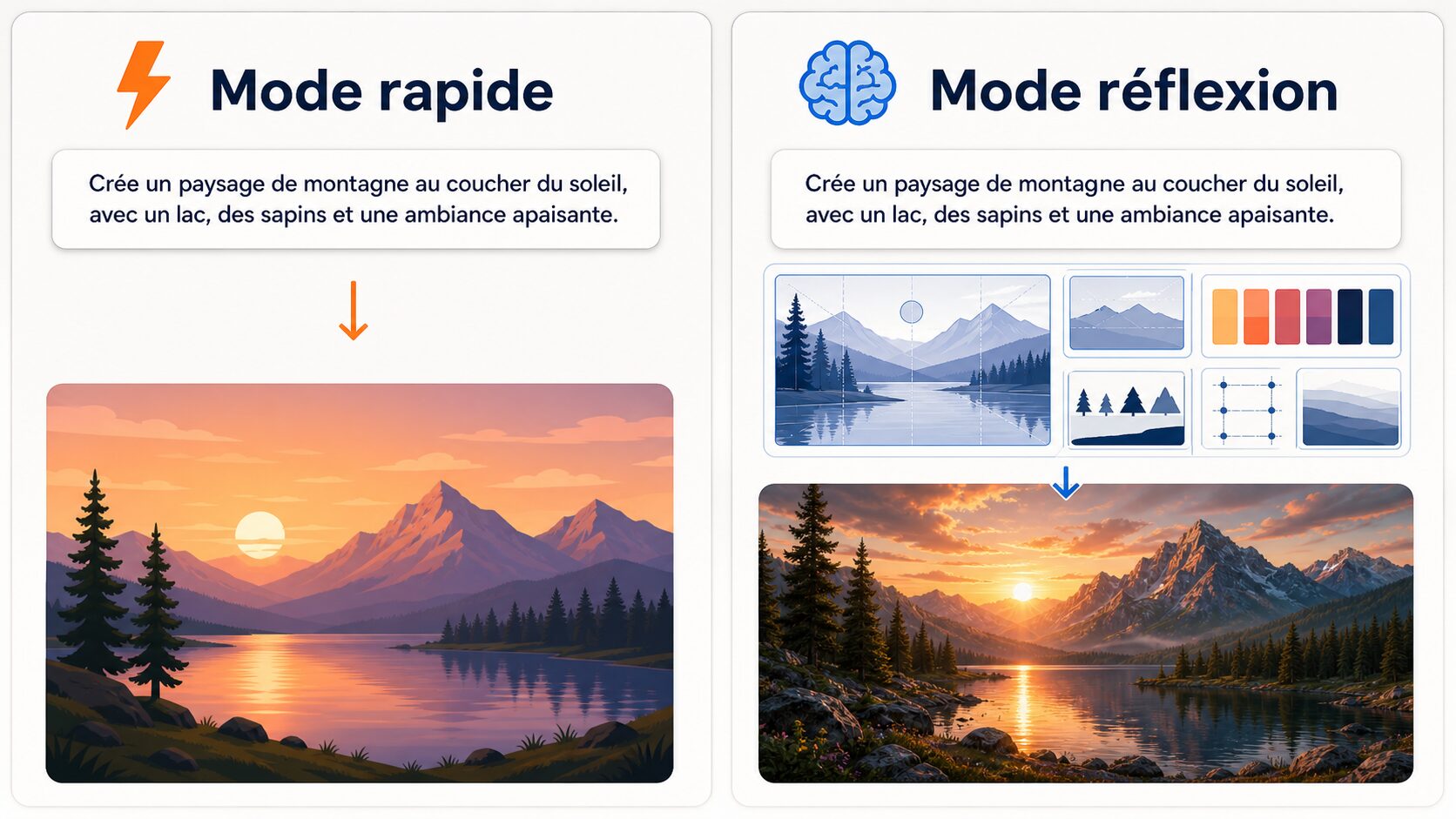
Deux façons de générer : rapide ou avec réflexion
Dans l’usage quotidien, il faut distinguer deux modes de travail. Le premier est le mode rapide : vous demandez une image simple, ChatGPT génère, vous récupérez un premier résultat. Le second est le mode avec réflexion : vous utilisez un modèle capable de prendre plus de temps pour planifier l’image avant de la produire.
Ce n’est pas un détail d’interface. C’est une décision de workflow.
Le mode rapide : pour explorer
Le mode rapide sert à tester une idée. Vous voulez une ambiance, une première direction, un moodboard, une image simple pour illustrer un concept, un brouillon de miniature, une scène sans texte complexe. Dans ce cas, inutile de surcharger le prompt. Une description claire suffit.
Crée une image carrée pour un post LinkedIn. Sujet : un entrepreneur indépendant qui utilise l’IA pour produire ses contenus plus vite. Style : photo réaliste, bureau moderne, lumière naturelle, ambiance calme et productive. Aucun texte dans l’image.
Ce type de prompt est parfait pour démarrer. Il donne un sujet, un format, un style, une ambiance et une contrainte. Pas besoin de lister trente détails. Le modèle comprend déjà le langage naturel.
Les images avec réflexion : pour produire
Dès que vous voulez un résultat publiable, passez à une logique de réflexion. C’est particulièrement utile quand l’image contient du texte, plusieurs zones, une composition précise, un produit, une marque, une hiérarchie visuelle ou un usage marketing.
Crée un visuel vertical 9:16 pour une story Instagram. Objectif : annoncer un webinaire sur la productivité avec l’IA. Style : éditorial premium, fond bleu nuit, lumière douce, ordinateur portable ouvert, carnet, tasse de café, ambiance professionnelle mais accessible. Texte exact à intégrer : « Gagnez 5 heures par semaine avec l’IA ». Sous-texte : « Webinaire gratuit — jeudi 18h ». Composition : titre très lisible en haut, scène de bureau au centre, sous-texte en bas. Prévois la hiérarchie visuelle avant de générer.
La différence est nette. Vous ne demandez plus seulement une belle image. Vous définissez une mission. Le modèle sait à quoi sert le visuel, où placer les éléments, quel texte respecter, quel canal viser, et quelle priorité donner à la lisibilité.
| Mode de travail | À utiliser pour | Prompt conseillé | Limite principale |
|---|---|---|---|
| Génération rapide | Idées, moodboards, images simples, exploration de styles | Court, clair, centré sur le sujet et l’ambiance | Moins fiable pour les compositions complexes |
| Images avec réflexion | Visuels publiables, texte intégré, mise en page, infographies, marketing | Brief complet : format, usage, hiérarchie, contraintes, texte exact | Plus lent, parfois plus coûteux via API |
| Retouche conversationnelle | Corriger une image existante sans tout refaire | Décrire uniquement ce qui doit changer et ce qui doit rester fixe | Les micro-détails doivent être vérifiés manuellement |
Où accéder à ChatGPT Images 2.0
Le point d’entrée principal est ChatGPT. OpenAI indique que ChatGPT Images 2.0 est disponible sur toutes les formules ChatGPT. En revanche, les images avec réflexion sont réservées aux formules payantes et s’utilisent avec les modèles Thinking et Pro.
En pratique, vous pouvez travailler de trois façons.
Dans une conversation ChatGPT
C’est le plus simple. Vous écrivez votre demande comme n’importe quel prompt. Vous pouvez ensuite continuer dans la même conversation : « rends le fond plus sombre », « remplace le titre par celui-ci », « fais une version 16:9 », « ajoute plus d’espace négatif à droite », « supprime le téléphone sur la table ».
Le vrai avantage est le contexte. ChatGPT garde le fil. Vous n’avez pas besoin de réexpliquer toute la scène à chaque variation. C’est cette continuité qui rend l’outil beaucoup plus pratique pour produire une série de visuels.
Depuis les applications mobile et desktop
Sur mobile, l’usage est particulièrement intéressant pour partir d’une photo existante : packaging, vitrine, plat de restaurant, croquis papier, tableau blanc, intérieur, tenue, maquette. Vous pouvez photographier, uploader, puis demander une transformation ou une retouche.
Sur desktop, le workflow est plus confortable pour les tâches de production : prompts longs, comparaison de variantes, téléchargement, renommage des fichiers, insertion dans WordPress, Canva, Figma, Photoshop ou une présentation.
Via l’API gpt-image-2
Pour les développeurs, OpenAI propose le modèle gpt-image-2. Il accepte du texte en entrée, peut recevoir et produire des images, et s’utilise notamment avec les endpoints de génération et d’édition d’images. C’est la porte d’entrée pour automatiser : générer des visuels d’articles à grande échelle, créer des variantes e-commerce, localiser des screenshots, produire des bannières multi-formats, ou intégrer la génération d’images dans un outil interne.
Nous consacrerons un article complet à l’API. Pour l’instant, retenez simplement ceci : l’interface ChatGPT sert à apprendre et produire manuellement. L’API sert à industrialiser.
Formats, ratios et résolution : ce qu’il faut comprendre
Un visuel raté commence souvent par un mauvais format. Une image pensée pour LinkedIn ne se compose pas comme une story Instagram. Une bannière 16:9 ne laisse pas les mêmes marges qu’un carré 1:1. Une infographie verticale ne se pense pas comme une miniature YouTube.
ChatGPT Images 2.0 prend en charge des formats beaucoup plus flexibles qu’ancienne génération. Côté API, gpt-image-2 accepte des dimensions personnalisées, avec trois contraintes importantes : chaque bord doit être un multiple de 16 pixels, le ratio entre le côté long et le côté court ne doit pas dépasser 3:1, et la taille totale doit rester dans les bornes acceptées par l’API. OpenAI indique également que les sorties au-delà de 2K restent plus variables selon les usages.
| Usage | Format conseillé | Pourquoi |
|---|---|---|
| Post LinkedIn / Instagram | 1:1 ou 4:5 | Lisibilité forte dans le feed, composition simple |
| Story / Reels / Shorts | 9:16 | Plein écran mobile, parfait pour texte + scène |
| Bannière web / hero section | 16:9 ou 3:1 | Espace horizontal pour titre, produit et zone négative |
| Miniature YouTube | 16:9 | Visuel large, contraste fort, texte court |
| Infographie | 4:5, 2:3 ou 1:3 | Lecture verticale, sections empilées, progression claire |
| Image produit e-commerce | 1:1 ou 4:5 | Produit centré, compatible catalogue et marketplace |
La règle simple : donnez le canal dès le prompt. Ne dites pas « crée une image sur l’IA ». Dites « crée un visuel 9:16 pour une story Instagram », ou « crée une bannière 3:1 pour le hero d’une landing page ». Le modèle composera l’image différemment.
Au 5 mai 2026, la documentation API indique que gpt-image-2 ne prend pas encore en charge les arrière-plans transparents. Si vous avez besoin d’un PNG détouré pour un logo ou un sticker, prévoyez une étape de détourage externe, ou demandez un fond uni très contrasté pour faciliter l’extraction.
Votre premier prompt professionnel
Un bon prompt image n’est pas une accumulation de mots-clés. C’est un brief. Il doit répondre à six questions :
- Quel est le sujet ? Personne, objet, scène, produit, interface, affiche, infographie.
- À quoi sert l’image ? Post social, publicité, miniature, article de blog, slide, email, packaging.
- Quel format ? 1:1, 16:9, 9:16, 3:1, portrait, paysage.
- Quel style ? Photo réaliste, éditorial premium, illustration flat, 3D, manga, poster vintage, UI moderne.
- Quels éléments doivent absolument apparaître ? Sujet, décor, objet, texte, logo fictif, couleur, ambiance.
- Quelles contraintes ? Texte exact, pas de watermark, fond simple, zone vide à gauche, produit centré, pas de mains visibles.
Voici un template simple à réutiliser :
Crée une image [FORMAT] pour [USAGE]. Sujet principal : [SUJET]. Scène : [DÉCOR + ACTION]. Style : [STYLE VISUEL]. Ambiance : [LUMIÈRE + COULEURS + ÉMOTION]. Éléments obligatoires : [LISTE]. Texte exact à intégrer : « [TEXTE] ». Composition : [PLACEMENT DES ÉLÉMENTS]. Contraintes : [CE QU’IL NE FAUT PAS FAIRE].
Et voici une version réellement testable :
Scene : Rustic wooden table, morning light filtering through a window, slightly out-of-focus kitchen in the background. Subject : A kraft paper coffee bag standing upright, label reads « TORRÉFACTION NOIRE » in bold vintage serif typography. Important details : Realistic paper texture with visible grain, small roasted coffee beans scattered at the base, warm golden tones, eye-level framing, natural shadows, 35mm lens feel. Use case : Product photography for artisan coffee brand website. Constraints : No plastic look, no generic stock feel, photorealistic.
Ce prompt marche mieux qu’un simple « fais une belle photo de café premium » parce qu’il verrouille quatre choses : la scène, la matière, le texte et l’usage. Le modèle ne doit pas deviner si l’image sert à une publicité, un packaging, un site e-commerce ou une publication sociale. Il sait ce qu’il doit produire.
Ce que ChatGPT Images 2.0 fait déjà très bien
Pour un premier article, inutile d’explorer toutes les possibilités. Mais vous devez voir ce que le modèle sait déjà produire quand le brief est suffisamment concret. Les exemples ci-dessous ne sont pas là pour décorer l’article : ils servent à montrer les forces réelles du modèle : texte intégré, mise en page, hiérarchie, rendu éditorial, matière, packaging et composition.





Le texte dans l'image
C'est la grande différence perçue par beaucoup d'utilisateurs. Les anciens modèles savaient créer de belles affiches, mais le texte finissait souvent en pseudo-anglais illisible. ChatGPT Images 2.0 améliore fortement ce point. Titres, labels, menus, couvertures, interfaces, petites zones de texte : le modèle devient beaucoup plus utile pour créer des visuels prêts à publier.
La règle reste simple : mettez le texte exact entre guillemets. Si vous écrivez seulement « ajoute un slogan sur l'image », le modèle peut improviser. Si vous écrivez « ajoute le texte exact : “Automatisez votre marketing sans recruter” », vous augmentez fortement vos chances d'obtenir le bon rendu.
Les compositions denses
OpenAI montre des exemples d'infographies, pages éditoriales, planches de manga, affiches avec typographie, supports pédagogiques et mises en page complexes. C'est une évolution importante : le modèle ne génère pas seulement un sujet au centre. Il peut organiser plusieurs zones, plusieurs éléments, plusieurs blocs de texte, plusieurs images dans une même composition.
La retouche
L'édition d'images est une autre force. Vous pouvez partir d'une image existante et demander un changement précis : modifier un objet, remplacer un fond, changer une couleur, prolonger un décor, réécrire un label, ou préserver une personne tout en changeant certains éléments. L'article 4 de cette série sera consacré à cette logique de retouche conversationnelle.
Les formats flexibles
Le passage d'un carré à un vertical, d'une bannière large à une story, ou d'une image d'article à une miniature devient beaucoup plus naturel. Attention cependant : changer un ratio n'est pas seulement recadrer. Il faut souvent recomposer. Une bonne demande ne dit pas seulement « passe en 9:16 ». Elle dit : « recompose en 9:16, garde le sujet au centre, place le titre en haut, conserve une marge basse pour les boutons de l'interface mobile ».
L'itération conversationnelle : le vrai superpouvoir
Avec les anciens générateurs d'images, l'utilisateur avait tendance à recommencer. Nouveau prompt, nouvelle image, nouveau hasard. Avec ChatGPT Images 2.0, la bonne méthode est différente : vous itérez dans la même conversation.
Après la première génération, ne repartez pas de zéro. Donnez une correction précise.
- « Garde la même composition, mais rends l'éclairage plus naturel. »
- « Le texte est trop petit. Agrandis le titre et simplifie le sous-titre. »
- « Conserve le personnage, mais remplace le fond par un bureau plus minimaliste. »
- « Fais une version 9:16 adaptée à une story, avec plus d'espace en haut. »
- « Supprime les objets inutiles sur la table. Garde seulement l'ordinateur, le carnet et la tasse. »
- « Rends le visuel moins futuriste et plus crédible pour une PME française. »
Ce vocabulaire est important. Vous ne demandez pas une « variante » vague. Vous dites ce qui reste fixe, ce qui change, et pourquoi. C'est exactement comme un brief de retouche.
La règle des trois passes
Pour un visuel publiable, utilisez une méthode en trois passes.
Générez une première image pour trouver l'ambiance : style, lumière, sujet, cadrage général. À ce stade, ne cherchez pas la perfection. Cherchez la bonne direction.
Corrigez le placement : sujet trop centré, texte trop bas, manque d'espace négatif, visuel trop chargé, produit pas assez visible. C'est ici que l'image devient utilisable.
Vérifiez les détails : texte, mains, logos, proportions, objets absurdes, cohérence de lumière, lisibilité mobile. C'est la passe qui sépare une image sympa d'un asset publiable.
Les plans et limites : gratuit, payant, API
OpenAI indique que ChatGPT Images 2.0 est disponible sur toutes les formules ChatGPT. Mais disponibilité ne veut pas dire même expérience pour tout le monde. Les limites d'usage, la vitesse, les modèles accessibles et la capacité à utiliser les images avec réflexion varient selon les plans.
La règle pratique est simple : le gratuit suffit pour tester. Les formules payantes deviennent nécessaires dès que vous voulez produire régulièrement. L'API devient pertinente si vous voulez automatiser ou intégrer la génération dans un outil.
| Accès | Ce que vous pouvez faire | Pour qui | Point d'attention |
|---|---|---|---|
| Formule gratuite | Découvrir la génération d'images dans ChatGPT | Curieux, tests ponctuels, premiers prompts | Limites d'usage plus basses et fonctionnalités avancées restreintes |
| Formules payantes | Produire plus souvent, accéder aux images avec réflexion selon les modèles disponibles | Créateurs, indépendants, marketeurs, formateurs, équipes contenu | Les plafonds peuvent évoluer : vérifiez toujours l'interface au moment de produire |
| API gpt-image-2 | Générer et éditer des images dans vos propres workflows | Développeurs, SaaS, e-commerce, médias, automatisation SEO | Facturation au token, qualité et résolution influencent le coût |
Pourquoi ne pas donner un chiffre fixe du type « X images toutes les trois heures » ? Parce qu'OpenAI ne publie pas toujours des quotas universels et permanents dans l'aide publique. Les plafonds peuvent varier selon la formule, le modèle, la charge, le pays et l'état du compte. Pour un article durable, le plus utile est donc de retenir la logique : gratuit pour tester, payant pour produire, API pour automatiser.
Côté API, les coûts sont plus précis. Au 5 mai 2026, la page tarifaire OpenAI liste gpt-image-2 à 8 $ par million de tokens image en entrée, 2 $ par million de tokens image en cache, et 30 $ par million de tokens image en sortie. Le texte en entrée est listé à 5 $ par million de tokens, avec 1,25 $ par million en cache. Ces prix peuvent changer : pour un usage en production, vérifiez toujours la page pricing officielle avant de lancer une génération en volume.
Ce que ChatGPT Images 2.0 ne fait pas encore parfaitement
Un bon workflow commence par les limites. ChatGPT Images 2.0 est impressionnant, mais ce n'est pas un directeur artistique autonome, ni un logiciel de PAO, ni une garantie de vérité factuelle.
Les petits textes restent à vérifier. Le rendu typographique a beaucoup progressé, mais les disclaimers minuscules, les paragraphes longs, les noms propres inhabituels ou les textes très serrés doivent être relus avant publication.
Les données factuelles doivent être contrôlées. Même si les images avec réflexion peuvent utiliser des outils et des données récentes dans certains workflows, vous devez vérifier les chiffres, dates, noms, citations et informations sensibles avant de publier une infographie.
Les détails techniques très précis restent fragiles. Plans d'étage, schémas avec flèches, diagrammes scientifiques, interfaces complexes, pictogrammes nombreux : le résultat peut être très bon visuellement, mais faux dans les détails. Pour un usage professionnel, l'image doit être relue comme une maquette, pas acceptée comme une vérité.
Le produit commercial exige un vrai brief. Un prompt vague comme « fais un packshot premium » donne souvent une image propre mais plate. Pour vendre, il faut une scène, une matière, une cible, une promesse, un usage et une raison de cliquer. C'est une compétence à part entière, que nous traiterons dans l'article suivant.
Les droits et personnes réelles demandent de la prudence. Ne générez pas n'importe quelle image avec le visage d'une personne réelle, un logo protégé, une marque concurrente, ou un style qui pourrait poser problème. OpenAI applique plusieurs couches de sécurité et de provenance, mais la responsabilité éditoriale finale vous appartient.
L'API n'est pas Photoshop. Elle génère et édite. Elle ne remplace pas encore une chaîne de production complète avec calques, vectorisation, contrôle typographique au pixel, exports print, marges techniques, profils colorimétriques et validation imprimeur.
Votre première configuration : les cinq choses à faire maintenant
Assez de théorie. Voici les cinq actions concrètes pour transformer ChatGPT Images 2.0 en outil de travail, et pas seulement en générateur de jolies images.
Ouvrez une nouvelle conversation ChatGPT et donnez-lui un rôle clair : « Tu es mon assistant de direction artistique pour créer des visuels publiables. » Gardez cette conversation pour vos tests images. Vous aurez ainsi un historique de prompts, de variantes et de corrections.
Générez la même idée en 1:1, 16:9 et 9:16. Observez ce qui change : placement du sujet, taille du texte, respiration, équilibre. C'est le moyen le plus rapide de comprendre que le format n'est pas un détail technique, mais une décision de composition.
Copiez le template de cet article et adaptez-le à votre activité. Si vous produisez des images pour un blog, ajoutez toujours : sujet, angle éditorial, style, format, espace négatif et interdiction de texte. Si vous produisez pour les réseaux, ajoutez canal, titre exact et lisibilité mobile.
Après la première image, forcez-vous à faire trois corrections dans la même conversation. Exemple : cadrage, lumière, simplification. Vous apprendrez plus vite qu'en lançant dix prompts différents.
Chaque fois qu'un prompt produit un bon résultat, sauvegardez-le avec le format, l'usage et la date. Dans un mois, cette bibliothèque vaudra plus qu'une liste de « 100 prompts magiques » trouvée sur LinkedIn.
Le test simple pour juger votre première image
Avant de publier, ne demandez pas « est-ce que l'image est belle ? ». Demandez plutôt :
- Est-ce qu'on comprend le sujet en moins de deux secondes ?
- Est-ce que le format correspond au canal ?
- Est-ce que le texte, s'il y en a, est parfaitement lisible ?
- Est-ce que l'image ressemble à votre marque ou à une image IA générique ?
- Est-ce qu'un détail absurde attire l'œil ?
- Est-ce que l'image sert vraiment l'objectif : clic, lecture, confiance, vente, mémorisation ?
Si la réponse est non à l'une de ces questions, ne supprimez pas l'image. Corrigez-la. C'est précisément là que ChatGPT Images 2.0 devient utile : dans la boucle de correction.
Ce que vous savez maintenant (et ce qui vient ensuite)
À ce stade, vous savez ce qu'est ChatGPT Images 2.0, pourquoi le modèle change la production visuelle, comment distinguer génération rapide et images avec réflexion, où accéder à l'outil, quels formats utiliser, comment écrire un premier prompt propre, et comment itérer sans repartir de zéro.
La base est posée. Mais le vrai levier arrive maintenant : apprendre à parler au modèle comme un directeur artistique. Pas avec une suite de mots-clés. Avec un brief visuel. Sujet, scène, style, lumière, cadrage, hiérarchie, contraintes, usage final. C'est ce que nous allons construire dans l'article suivant.
La qualité d'une image IA ne dépend pas seulement du modèle. Elle dépend du brief. Structure de prompt, vocabulaire photo, contraintes de composition, texte exact, styles, erreurs à éviter : la méthode complète pour obtenir des visuels vraiment contrôlés.