Mémoire de Claude : comment il apprend de vous et comment la piloter
Vous ouvrez une nouvelle conversation avec Claude. Il connaît déjà votre prénom, votre métier, vos projets en cours — sans que vous ayez rien re-saisi. Pratique. Mais savez-vous ce qu’il a retenu d’autre ? Savez-vous comment corriger ce qu’il a mal compris, supprimer ce qui est obsolète, ou lui faire mémoriser une information précise ? La mémoire de Claude fonctionne en coulisses, et la plupart des utilisateurs ne la consultent jamais. Une mémoire bien pilotée transforme pourtant la pertinence de chaque échange.
Un LLM n’a pas de mémoire au sens humain du terme. Quand vous fermez une conversation et en ouvrez une autre, Claude ne se « souvient » de rien par magie. Sa fenêtre de contexte — même à un million de tokens pour Opus 4.8, Sonnet 5 et Fable 5 — fonctionne comme un espace de travail temporaire. La mémoire de Claude est un système construit autour du modèle, pas dans le modèle. Ce mécanisme extrait des informations de vos conversations, les synthétise, puis les rend disponibles dans les échanges suivants. Comprendre cette distinction change complètement la façon dont vous l’utilisez.
Dans les articles précédents, vous avez configuré vos premiers réglages, maîtrisé le prompting, puis structuré vos Projects. La mémoire est la couche qui rend tout le reste cumulatif : au lieu de configurer Claude une fois et de s’arrêter là, vous construisez un système qui s’affine à chaque utilisation.
La mémoire ne remplace pas vos Projects, vos préférences ou vos instructions. Elle ajoute une couche d’apprentissage continu : Claude retient votre contexte professionnel, vos préférences de travail, vos projets récurrents et certains détails utiles pour mieux répondre dans les conversations suivantes.
Le mécanisme en trois temps : extraction, synthèse, injection
Depuis mars 2026, la mémoire de Claude est disponible pour tous les utilisateurs — Free, Pro, Max, Team et Enterprise — sur le web, Claude Desktop et Claude Mobile. Selon votre compte, elle peut être activée ou désactivée dans Réglages > Capacités. Elle fonctionne en trois étapes distinctes, et chacune a ses implications pratiques.
Extraction. Pendant vos conversations, Claude identifie les informations qui méritent d’être retenues : votre métier, vos préférences de communication, vos projets en cours, les outils que vous utilisez, les décisions que vous avez prises. Le système privilégie le contexte professionnel — il retient mieux vos préférences de travail que les anecdotes personnelles.
Synthèse. Claude consolide les informations extraites de vos conversations en une synthèse cohérente, mise à jour dans un délai d’environ 24 heures. Celle-ci fusionne les nouvelles données avec les existantes, résout les contradictions quand c’est possible, puis retire ce qui provient de conversations supprimées. Le résultat est un portrait synthétique de vous et de votre contexte de travail.
Injection. Au début d’une nouvelle conversation hors Project, Claude peut charger cette synthèse dans son contexte. C’est pour ça qu’il « sait » des choses sur vous dès le premier message — il ne s’en souvient pas comme un humain, il récupère un résumé maintenu par le système de mémoire.
Conséquence pratique importante : si vous venez d’avoir une conversation où vous avez partagé des informations clés, elles ne seront pas forcément disponibles dans la conversation suivante immédiate. Le cycle de synthèse n’est pas instantané. Pour des informations que vous voulez disponibles tout de suite, utilisez les memory edits — ils sont appliqués immédiatement à la conversation suivante.
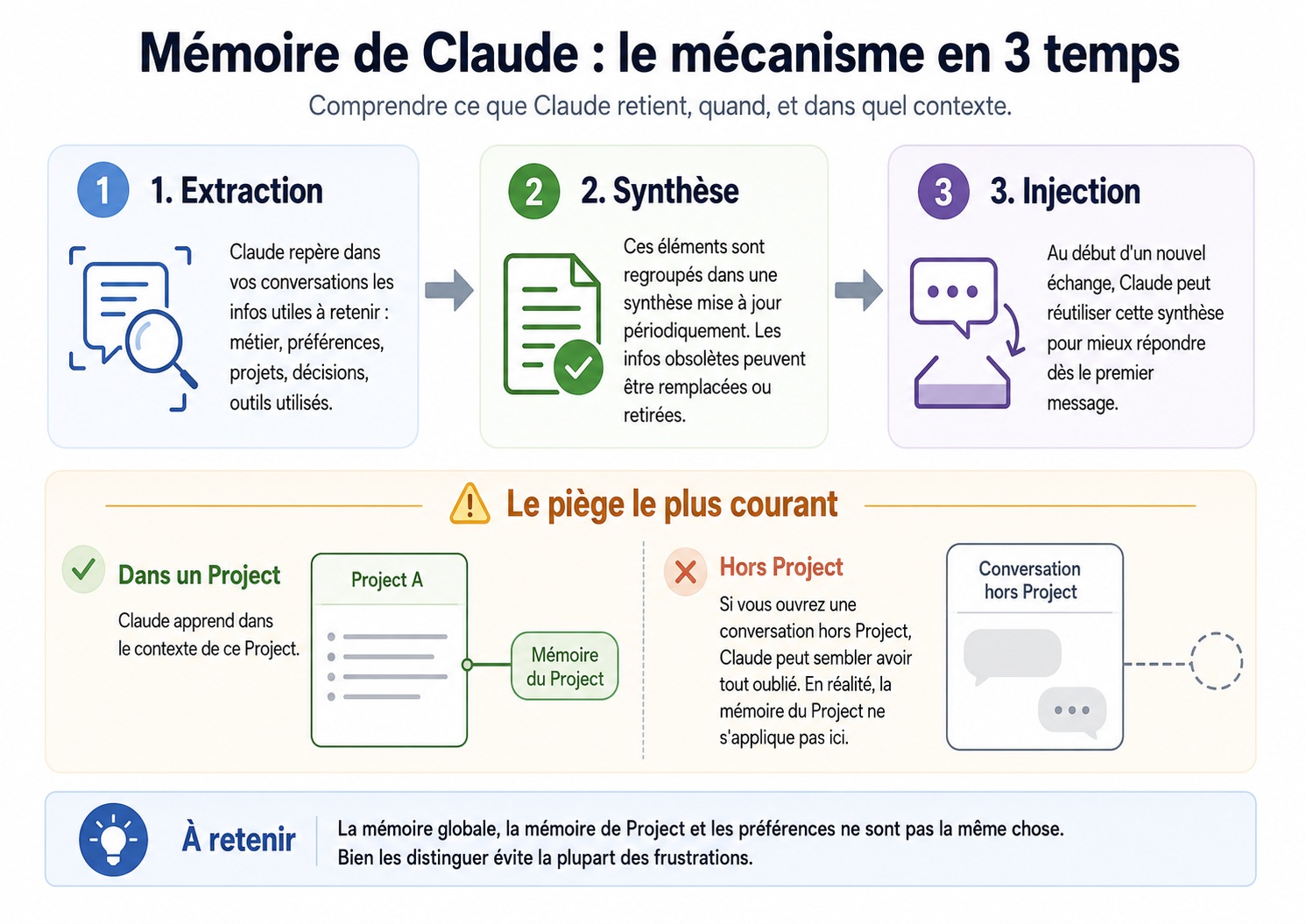
Mémoire globale vs. mémoire de Project : deux espaces séparés
Claude maintient deux espaces de mémoire distincts, et la confusion entre les deux est la source d’erreur la plus fréquente.
La mémoire globale se construit à partir de vos conversations hors Project. Elle alimente ensuite vos futures conversations hors Project. C’est votre profil général : qui vous êtes, comment vous travaillez, ce que vous préférez.
La mémoire de Project, elle, se construit uniquement à partir des conversations dans un Project donné. Elle alimente uniquement les futures conversations dans ce même Project. Un Project « Blog IA » ne sait rien de ce que vous faites dans votre Project « Client X », et inversement. Cette isolation est voulue : elle empêche le contexte d’un domaine de contaminer un autre.
| Caractéristique | Mémoire globale | Mémoire de Project |
|---|---|---|
| Source | Conversations hors Project | Conversations dans le Project |
| Portée | Conversations standalone | Ce Project uniquement |
| Mise à jour | Environ 24 heures | Résumé propre au Project |
| Edits manuels | Oui, effet immédiat sur les prochaines conversations | Oui, effet immédiat dans le Project concerné |
| Suppression conversation | Données retirées de la synthèse | Données retirées du résumé Project |
Cette séparation explique un comportement qui surprend beaucoup d’utilisateurs : vous passez des heures à travailler dans un Project, puis vous ouvrez une conversation hors Project et Claude semble avoir « oublié » tout ce travail. Il n’a rien oublié — il n’a tout simplement jamais eu ces informations dans sa mémoire globale, parce qu’elles appartiennent à la mémoire du Project.
Consulter et modifier la mémoire : le panneau de contrôle
Rendez-vous dans Réglages > Capacités > Mémoire, puis cliquez sur « Voir et modifier la mémoire ». Vous y trouverez la synthèse complète de ce que Claude a retenu de vous. Lisez-la attentivement — la plupart des utilisateurs découvrent des informations obsolètes, des approximations, ou des lacunes importantes.
Les memory edits : corrections chirurgicales
Vous pouvez modifier la mémoire de Claude de deux façons. La première : directement depuis le panneau de réglages, en cliquant sur l’icône de modification. La seconde, plus naturelle : directement dans la conversation. Dites à Claude « Retiens que je travaille maintenant chez X » ou « Oublie mon ancien poste chez Y » — il met à jour sa synthèse sans attendre le prochain cycle de 24 heures.
Les memory edits sont l’outil le plus sous-estimé du système. Trois cas d’usage critiques :
- Corriger une erreur — Claude a déduit de vos conversations que vous êtes développeur alors que vous êtes chef de projet. Un edit corrige ça en une phrase, et les futures réponses seront calibrées correctement.
- Ajouter du contexte stratégique — « Retiens que mon objectif ce trimestre est de lancer trois nouveaux produits avant juillet. » Claude intègre alors cette priorité dans ses recommandations et ses analyses.
- Supprimer du bruit — Claude a retenu une conversation exploratoire où vous testiez des idées que vous avez finalement abandonnées. Supprimez ces éléments pour éviter qu’ils polluent les futures réponses.
Évitez de partager dans une conversation classique des mots de passe, numéros de carte bancaire, identifiants clients, données médicales ou éléments couverts par une obligation de confidentialité. Pour les échanges qui ne doivent pas être enregistrés dans l’historique ou la mémoire, utilisez le mode Incognito. Sur Team et Enterprise, les chats incognito peuvent malgré tout rester inclus dans les exports et politiques de rétention de l’organisation.
La recherche dans les conversations passées
Depuis mars 2026, Claude peut rechercher dans vos anciennes conversations pour retrouver un contexte précis. Cette fonctionnalité — Chat Search — est distincte de la mémoire synthétique. La mémoire donne à Claude une vue d’ensemble de votre profil. La recherche lui permet également de retrouver un échange spécifique : « Qu’est-ce qu’on avait décidé pour le pricing du produit Y ? »
Chat Search est disponible sur les plans payants (Pro, Max, Team, Enterprise). Elle peut couvrir les conversations hors Project et les conversations d’un Project précis, mais les recherches restent limitées au périmètre concerné. Quand Claude cite une information tirée d’une conversation passée, il peut ajouter une référence vers l’échange original — vous pouvez vérifier le contexte d’origine.
La combinaison mémoire + recherche change fondamentalement l’usage de Claude sur la durée. D’un côté, la mémoire gère le « qui suis-je et comment je travaille ». De l’autre, la recherche gère le « qu’est-ce qu’on avait dit sur ce sujet précis ». Les deux ensemble donnent à Claude une continuité que les conversations isolées ne peuvent pas offrir.
Importer sa mémoire depuis un autre assistant IA
Si vous migrez vers Claude depuis un autre assistant IA, vous pouvez importer votre mémoire existante. La fonction d’import est disponible sur les plans Free, Pro et Max, sur le web et Claude Desktop. Le principe est simple : vous exportez ce que votre ancien assistant sait de vous, vous collez ce contenu dans l’outil d’import Claude, puis Claude extrait les éléments utiles et les stocke comme memory edits.
En pratique, cela peut servir si vous venez de ChatGPT, Gemini, Grok ou d’un autre outil dans lequel vous avez déjà construit un historique. La documentation Anthropic fournit même un prompt d’export à copier dans votre ancien assistant pour récupérer vos préférences, projets, corrections et habitudes d’usage. Claude met ensuite la mémoire à jour dans un délai pouvant aller jusqu’à 24 heures.
Deux précautions après l’import. D’abord, vérifiez la synthèse résultante dans Réglages > Mémoire. L’import privilégie le contexte professionnel et peut mal interpréter certaines nuances. Ensuite, comptez une dizaine de minutes pour nettoyer les éléments inexacts ou redondants. Ce temps de vérification est un investissement qui évite des semaines de réponses mal calibrées.
Stratégie de mémoire : construire un profil qui travaille pour vous
La mémoire passive laisse Claude accumuler des bribes d’information au fil des conversations, et produit un profil brouillon. La mémoire active vous permet de piloter ce que Claude retient, et produit ainsi un profil qui améliore concrètement chaque échange. Voici la méthode en quatre étapes.
Ouvrez Réglages > Mémoire et lisez tout ce que Claude a retenu. Identifiez ensuite trois catégories : le correct (à garder), l’obsolète (à supprimer), et le manquant (à ajouter). La plupart des utilisateurs trouvent au moins 20 % d’informations périmées dès le premier audit.
Dites explicitement à Claude les informations qu’il doit retenir : votre poste actuel, vos responsabilités, vos outils quotidiens, les sujets sur lesquels vous travaillez ce trimestre, vos préférences de livraison (format, longueur, ton). Chaque edit est alors une instruction durable qui améliore les futures conversations.
Supprimez les conversations exploratoires qui ont généré des données parasites. Supprimez également les memory edits devenus obsolètes. Si vous avez changé de poste, de projet ou d’orientation, la mémoire doit refléter votre situation actuelle, pas votre historique.
Planifiez un audit de 10 minutes par mois. Vérifiez que la synthèse est à jour, supprimez ce qui a changé, ajoutez enfin les nouveaux contextes. Comme les instructions de Project, une mémoire non maintenue se dégrade progressivement. La maintenance est ce qui sépare un système cumulatif d’un système qui accumule du bruit.
Mémoire, Projects et préférences : comment tout s’articule
Trois systèmes de personnalisation coexistent dans Claude. Comprendre leur hiérarchie évite ainsi les redondances et les conflits.
Les préférences de profil définissent vos règles universelles (ton, format, niveau technique). Elles s’appliquent partout, tout le temps. C’est le socle.
La mémoire ajoute un portrait évolutif construit à partir de vos conversations. Elle enrichit également le contexte avec des informations que vous n’avez pas explicitement configurées dans vos préférences — vos projets en cours, vos décisions récentes, vos habitudes d’usage. Elle complète ainsi le socle.
Les instructions de Project ajoutent enfin un contexte spécifique à un domaine de travail : les règles métier, les fichiers de référence, les contraintes du projet. Elles surclassent les préférences et la mémoire quand il y a contradiction.
L’ordre pratique à retenir : préférences de profil → mémoire → instructions de Project. Chaque couche affine ainsi la précédente. Quand les trois sont bien calibrées, Claude produit des réponses personnalisées dès le premier message, sans re-contextualisation lourde de votre part. C’est l’objectif de cette série depuis le début : construire un système où la qualité des réponses est structurelle, pas accidentelle.
Vie privée et contrôle : ce que vous devez savoir
La mémoire soulève des questions légitimes sur ce que Claude sait de vous et ce qu’il en fait. Voici les réponses factuelles.
Le contrôle reste entre vos mains. Chaque élément de la mémoire peut être consulté, modifié ou supprimé à tout moment. La mémoire peut également être mise en pause (Claude garde ses données mais ne les utilise plus) ou réinitialisée entièrement (suppression irréversible de toute la synthèse).
Les conversations incognito n’alimentent pas la mémoire. Activez le mode incognito (icône fantôme en haut à droite) quand vous voulez interagir avec Claude sans que la conversation soit enregistrée dans votre historique ou intégrée à la mémoire. Le mode incognito est disponible hors Project, sur tous les plans.
La suppression d’une conversation retire ses données de la synthèse. Si vous supprimez une conversation, les informations qu’elle avait contribuées à la mémoire sont ensuite retirées lors du prochain cycle de synthèse. Claude indique que la mémoire se met à jour dans un délai d’environ 24 heures quand des conversations sont créées, modifiées ou supprimées.
L’utilisation pour l’entraînement dépend de vos réglages et de votre plan. Sur les plans Free, Pro et Max, vérifiez le réglage de confidentialité lié à l’amélioration de Claude. Si vous autorisez l’utilisation de vos chats ou sessions de code pour améliorer Claude, Anthropic peut conserver ces données jusqu’à 5 ans dans ses pipelines d’entraînement, pour les nouveaux chats ou sessions repris après activation du réglage. Si vous n’autorisez pas cette utilisation, la durée de rétention standard reste de 30 jours. Les produits commerciaux comme Claude for Work, Team, Enterprise, l’API, Bedrock ou Vertex AI ne sont pas utilisés par défaut pour entraîner les modèles.
La mémoire comme accélérateur
Une mémoire pilotée activement fait gagner du temps à chaque conversation. Plus de re-contextualisation, plus d’explications redondantes, plus de résultats génériques. Claude commence chaque échange avec une compréhension de votre situation — pas parfaite, mais substantiellement meilleure qu’une page blanche.
Combinée avec des préférences de profil bien rédigées et des Projects correctement structurés, la mémoire ferme la boucle du système de personnalisation. Vous avez maintenant les trois couches qui font de Claude un outil calibré sur mesure : les règles (préférences), le contexte de travail (Projects), et l’apprentissage continu (mémoire).
Jusqu’ici, vous avez calibré Claude sur vous. Maintenant, on passe à l’action : recherche web, Chat Search et Research. Comment faire de Claude une machine de veille et de sourcing, capable de remplacer des heures de recherche par une conversation structurée.