Génération d’images : gpt-image-2 et ChatGPT Images 2.0
Vous demandez à ChatGPT une infographie pour un rapport, avec un tableau chiffré et un label en mandarin. ChatGPT Images 2.0 et son moteur gpt-image-2 la rendent lisible du premier coup . En effet, le modèle raisonne avant de dessiner, produit huit images cohérentes d’un seul coup et rend le texte avec une précision proche de 100 %. Ce septième article de la série vous montre ce que cela débloque concrètement.
ChatGPT Images 2.0, alimenté par le modèle gpt-image-2, est le modèle de génération d’images par défaut de ChatGPT depuis le 21 avril 2026. Il repose sur trois sauts techniques : un rendu de texte enfin fiable, un mode Thinking qui raisonne avant de générer, puis la capacité à produire jusqu’à huit images cohérentes depuis un seul prompt.
Ce guide couvre les faits techniques, les deux modes d’usage, les quatre nouvelles primitives créatives, le prompting adapté au modèle, les points d’intégration dans un workflow, puis les limites honnêtes à connaître avant de s’engager.
Ce que change gpt-image-2 face à gpt-image-1.5
Les faits bruts d’abord. gpt-image-2 ne remplace pas simplement le modèle précédent par incrément de qualité : il change ainsi plusieurs paramètres de fond qui conditionnent ce que vous pouvez lui demander.
| Capacité | gpt-image-1.5 (ancien) | gpt-image-2 (actuel) |
|---|---|---|
| Rendu du texte | Lisible ~90 % en anglais, faible en non-latin | Quasi 100 % en blind tests, multilingue solide |
| Raisonnement avant génération | Aucun | Mode Thinking avec recherche web et auto-vérification |
| Images par prompt | 1 | Jusqu’à 8 cohérentes (mode Thinking) |
| Édition multi-turn | Dérive visible après 2-3 retouches | Cohérence maintenue sur enchaînements longs |
| Résolution maximum | 1024×1024 standard | Jusqu’à 2K natif, 4K via hébergeurs tiers |
| Ratios d’aspect | Carré, 16:9, 9:16 | 3:1 à 1:3, formats presse inclus |
| Knowledge cutoff | Avril 2024 | Décembre 2025 |
| Vitesse de génération | 4 à 8 secondes | ~3 secondes en mode Instant |
La cohérence multi-turn mérite une ligne à part. Avant gpt-image-2, enchaîner plusieurs retouches sur la même image dégradait systématiquement le résultat—un fond changé décalait l’éclairage du sujet, un logo ajouté déplaçait les proportions. Le nouveau modèle tient sur l’enchaînement : un fond remplacé puis un logo ajouté puis une couleur modifiée préservent l’image d’origine. C’est l’un des cinq progrès majeurs revendiqués par OpenAI au lancement.
Côté droits d’usage, rien ne change : les images générées vous appartiennent et sont exploitables commercialement, y compris sur le plan gratuit. Les fichiers intègrent des métadonnées C2PA qui tracent leur origine IA—un standard de transparence en progression dans l’industrie.
DALL-E 2 et DALL-E 3 ont été retirés le 12 mai 2026. gpt-image-1.5 reste accessible en API pour le support des intégrations existantes, mais n’est plus le modèle par défaut.
Instant ou Thinking : deux modes, deux usages
ChatGPT Images 2.0 se décline en deux modes qui ne jouent pas dans la même catégorie. Comprendre où se situe la frontière évite de payer un abonnement inutile ou de sous-exploiter le modèle.
Mode Instant : disponible pour tous, y compris le plan gratuit
Le mode Instant apporte les gains de qualité de base : meilleur rendu de texte, meilleur suivi d’instructions, placement d’objets précis, support multilingue. Il répond en quelques secondes, sans étape de raisonnement visible. Pour un visuel LinkedIn, une illustration d’article, un mockup rapide ou une variation de produit, Instant suffit largement. C’est également lui qui tourne par défaut dans l’onglet Images de ChatGPT, quel que soit votre plan.
Mode Thinking : réservé aux plans payants
Le mode Thinking est disponible sur les plans Plus, Pro, Business et Enterprise. Il débloque quatre capacités absentes d’Instant : la recherche web pendant la génération, le batch de huit images cohérentes depuis un seul prompt, la planification de layout pour les compositions denses, puis l’auto-vérification des sorties. Le modèle produit plusieurs candidats en interne, les compare au brief, puis régénère si l’écart est trop grand.
Conséquence directe : Thinking est plus lent (quelques dizaines de secondes au lieu de quelques-unes) et plus coûteux, car facturé sur les tokens de raisonnement en plus des tokens image.
Infographies avec données à jour, storyboards multi-panneaux, character sheets cohérents, campagnes multi-formats à partir d’un même brief, visuels avec texte dense et layout contraint. Pour un simple visuel LinkedIn ou une illustration d’article, le mode Instant fait le travail plus vite et moins cher.
Les quatre nouvelles primitives créatives
Au-delà des chiffres techniques, gpt-image-2 débloque quatre capacités qui étaient inutilisables en production jusqu’ici. Ce sont elles qui justifient de tester le modèle même si vous étiez satisfait de gpt-image-1.5.
Le rendu de texte multilingue fiable
gpt-image-2 atteint une précision quasi parfaite sur les titres, labels UI, signalétiques et textes multilingues courts, y compris en tests à l’aveugle. Le japonais, le coréen, le chinois, le hindi et le bengali passent enfin la barre de lisibilité—c’était un angle mort persistant des générateurs d’images jusque-là. Une affiche manga avec kanjis justes ou un billboard en Inde avec titre en devanagari correct devient alors un livrable direct plutôt qu’un brouillon à retoucher. Les paragraphes longs et la reproduction pixel-parfaite d’un logo existant restent néanmoins imparfaits.
Le batch cohérent jusqu’à huit images
En mode Thinking, un seul prompt produit jusqu’à huit images qui partagent la même charte, les mêmes personnages, la même palette. Cette primitive débloque trois usages distincts. D’abord, les campagnes multi-formats : un même brief génère en un appel le carré Instagram 1:1, la bannière Twitter 3:1, le header LinkedIn large, puis l’image OG Facebook. Ensuite, les character sheets : un personnage vu de face, de trois-quarts, de profil, en action, avec la même identité visuelle sur les huit vignettes. Enfin, les storyboards et planches séquentielles pour la bande dessinée, le jeu indé ou les livres jeunesse. La cohérence n’est pas pixel-parfaite, mais elle suffit largement pour un premier jet exploitable par un studio.
Les artefacts techniques qui ne marchaient jamais avant
QR codes fonctionnels, diagrammes scientifiques annotés, plans de bâtiment, menus de restaurant avec prix alignés, posters d’infographie dense. Les modèles précédents rataient systématiquement ces formats parce qu’ils demandent à la fois de la précision typographique et de la logique structurelle. gpt-image-2 passe ainsi la barre sur ces cas, ce qui ouvre toute une catégorie de livrables qui devaient jusqu’ici passer par un outil de design dédié ou un générateur spécialisé.
La recherche web pendant la génération
En mode Thinking, le modèle peut interroger le web pendant qu’il compose l’image. Demandez-lui une infographie sur les derniers chiffres d’un marché, il va chercher les données publiques actuelles, puis les intègre directement dans le visuel. Lors de la démo de lancement, OpenAI a demandé au modèle de parcourir sa propre boutique en ligne et de générer une publicité avec les produits réellement en stock ce jour-là. Ce n’est plus de la génération d’image, c’est un agent visuel qui enquête avant de livrer. Pour une rédaction qui produit de l’explainer quotidien, cette capacité rejoint la logique de Deep Research sur du texte : un agent qui cherche avant de produire.
Prompter gpt-image-2 : le brief plutôt que la description
Changement de mental model important. gpt-image-2 répond mieux à un brief qu’à une description exhaustive. « Affiche pour startup fintech qui vise des DAF sceptiques de l’IA, ton rassurant institutionnel, pas de hype » produit un meilleur résultat que « Affiche bleu marine avec graphique en hausse, personnage en costume, logo en bas à droite ». Le modèle raisonne sur l’intention, l’audience et la contrainte. Écrivez vos prompts comme vous briefez un designer, pas comme vous décrivez une photo déjà existante.
Structure d’un prompt qui marche
Pour les cas où une description structurée reste pertinente (mockups précis, visuels avec texte exact), la grille suivante reste efficace. Les blocs [SUJET] et [TEXTE] portent désormais un poids réel dans le résultat final—ce qui était optionnel sur gpt-image-1.5 devient discriminant.
# Structure d'un prompt image professionnel
[SUJET] : Quoi exactement — objet, scène, personne, concept
[STYLE] : Photoréaliste, illustration vectorielle, aquarelle,
flat design, 3D isométrique, cinématique, manga
[COMPOSITION] : Plan large, gros plan, vue aérienne,
centré, rule of thirds, grille labellisée
[ÉCLAIRAGE] : Lumière naturelle, golden hour, studio,
néon, clair-obscur
[COULEURS] : Palette précise ou ambiance (tons chauds,
pastel, monochrome, couleurs corporate)
[TEXTE] : Titres, labels, légendes exacts à inclure
(entre guillemets dans le prompt)
[FORMAT] : 1:1, 16:9, 9:16, 3:1, 1:3, fond transparent
Trois exemples avant/après
Prompt faible : « Fais-moi un visuel pour un post LinkedIn sur le télétravail. »
Résultat : une image générique d’ordinateur portable sur un bureau.
Prompt pro : « Photo réaliste d’un espace de travail à domicile, vue en légère plongée. Bureau en bois clair, écran externe affichant le titre ‘Q2 Sales Review’ en haut à gauche, tasse de café, plante verte en arrière-plan. Lumière naturelle latérale, tons neutres et chaleureux. Ratio 16:9 pour LinkedIn. »
Résultat avec gpt-image-2 : un visuel publiable, avec le texte « Q2 Sales Review » lisible sur l’écran—ce qui était hasardeux sur gpt-image-1.5.

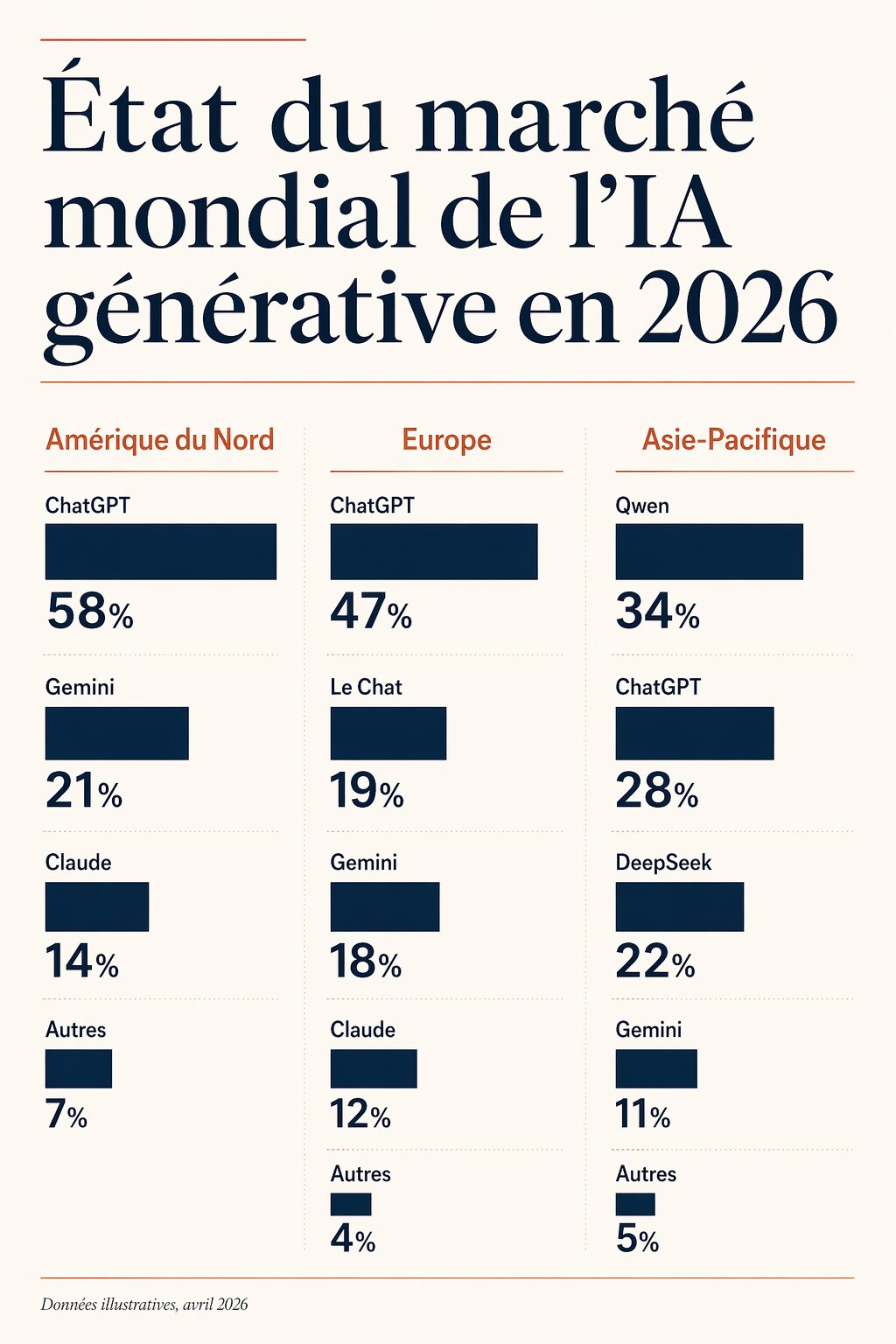
Prompt complexe : infographie multilingue avec données : « Infographie verticale format A4 portrait, style éditorial magazine. Titre principal en haut : ‘État du marché mondial de l’IA générative en 2026’. En dessous, trois colonnes parallèles : colonne 1 libellée ‘Amérique du Nord’ avec un graphique en barres montrant quatre valeurs (ChatGPT 58%, Gemini 21%, Claude 14%, Autres 7%) ; colonne 2 libellée ‘Europe’ avec les mêmes catégories (ChatGPT 47%, Le Chat 19%, Gemini 18%, Claude 12%, Autres 4%) ; colonne 3 libellée ‘Asie-Pacifique’ avec Qwen 34%, ChatGPT 28%, DeepSeek 22%, Gemini 11%, Autres 5%. Chaque barre porte son pourcentage en gros caractères. Palette : fond crème, barres en bleu marine profond et terracotta pour l’accent, typographie serif pour le titre, sans-serif pour les données. En bas, une note de source ‘Données illustratives, avril 2026’ en italique petit. Composition aérée, lignes de grille discrètes, aucun pictogramme superflu. »
Résultat attendu avec gpt-image-2 en mode Thinking : une infographie publiable telle quelle, avec les quinze valeurs numériques correctement placées, les titres de colonne lisibles, la hiérarchie typographique respectée et la palette tenue sur l’ensemble. C’est exactement le type de livrable qui demandait auparavant deux heures de mise en page dans Figma ou InDesign.
Intégrer gpt-image-2 dans un workflow
Le modèle est accessible par quatre chemins différents, chacun avec ses contraintes et son public cible. Choisir le bon point d’entrée dépend moins du niveau technique que du type de livrable final.
Dans l’interface ChatGPT
L’onglet Images est le point d’entrée principal dans la barre latérale. Pour activer Thinking, sélectionnez le mode Thinking (plans payants) avant d’envoyer le prompt—le moteur d’images bascule ensuite en conséquence. L’édition par sélection reste le geste quotidien le plus utile, avec une cohérence entre éditions nettement meilleure qu’avant : un logo ajouté dans un coin ne décale plus l’éclairage du reste de l’image, un fond changé préserve mieux le sujet.
Décrivez l’image souhaitée dans le chat, ou uploadez une photo existante à modifier. Le modèle accepte les inputs image en haute fidélité.
Cliquez sur l’image puis sur l’icône Éditer. Surlignez la zone concernée : fond, objet, texte, couleur.
Tapez l’instruction : « Remplace le fond par un paysage urbain la nuit », « Ajoute un logo dans le coin supérieur gauche », « Change la couleur du mur en bleu marine ».
Répétez pour d’autres zones. En mode Thinking, demandez directement huit variantes d’un même concept—le modèle maintient la cohérence visuelle sur l’ensemble du set.
Dans Codex pour les développeurs
gpt-image-2 est intégré nativement dans Codex, l’environnement de développement d’OpenAI. Les développeurs génèrent des mockups UI, des icônes, des directions visuelles sans quitter leur workspace et sans configurer une clé API séparée. Pour une base de développeurs Codex large et en croissance, cela supprime ainsi le point de friction majeur du prototypage visuel : plus de bascule entre éditeur de code et outil de design pour tester une maquette.
Dans Figma, Canva et Adobe Firefly
Figma, Canva, Adobe Firefly, fal et Hermes Agent ont intégré gpt-image-2 dès son lancement. Pour une créatrice de contenu qui travaille déjà dans Canva, le modèle arrive directement dans l’éditeur sans passer par l’interface ChatGPT. C’est rare pour un lancement de modèle et cela accélère fortement l’adoption réelle en production. Pour les équipes qui cherchent à s’équiper, le gain est immédiat : aucun changement d’outil, juste un nouveau moteur sous le capot.
Via l’API pour les intégrations sur mesure
L’API publique gpt-image-2 est disponible pour les développeurs. La facturation se fait au token : 8 $ par million de tokens image en entrée, 2 $ pour les inputs image mis en cache (références répétées), 30 $ par million de tokens image en sortie, puis 5 $ par million de tokens texte. En pratique, une image 1024×1024 revient autour de 0,006 $ en basse qualité, 0,053 $ en moyenne et 0,211 $ en haute qualité, selon la complexité du prompt. L’API Batch réduit également ces tarifs de 50 % si vous tolérez jusqu’à 24 h de latence. Détail pratique : l’alias chatgpt-image-latest pointe toujours vers le modèle image par défaut d’OpenAI, ce qui évite de recâbler votre code à chaque nouvelle version. Les workflows automatisés via Zapier, Make ou n8n qui pointaient vers l’endpoint DALL-E doivent basculer vers gpt-image-2, DALL-E ayant été retiré le 12 mai 2026.
| Plan ChatGPT | Accès mode Instant | Accès mode Thinking |
|---|---|---|
| Free | Oui, avec limites quotidiennes | Non |
| Plus | Oui, limites élargies | Oui |
| Pro | Oui, limites élevées | Oui, avec accès ImageGen Pro étendu |
| Business / Enterprise | Oui, limites workspace | Oui, selon politique du workspace |
Les limites honnêtes de gpt-image-2
OpenAI reconnaît quatre zones où le modèle continue de trébucher. Les objets à géométrie physique complexe : Rubik’s cubes avec reflets cohérents, guides origami, objets sur surfaces inclinées ou inversées. Le modèle manque d’un modèle physique robuste sur ces cas.
Les détails très fins ou répétitifs : grains de sable, textures denses, diagrammes techniques avec beaucoup de petites annotations. Les labels peuvent encore demander une relecture manuelle.
La reproduction exacte de logos existants : plusieurs testeurs rapportent que le modèle restitue parfois des versions périmées d’un logo, même avec correction explicite. Pour tout travail où l’identité visuelle doit être pixel-perfect, la retouche manuelle reste obligatoire.
Les événements et produits post-décembre 2025 : le knowledge cutoff du modèle est décembre 2025. Tout visuel lié à une actualité ou un produit émergent après cette date sera approximatif ou factuellement faux. Le mode Thinking compense partiellement avec la recherche web, mais la connaissance visuelle sous-jacente s’arrête à décembre 2025.
Les filtres de sécurité restent également actifs : contenus violents, sexuels, haineux et reproduction de personnages sous copyright sont bloqués. Les images de personnes publiques sont autorisées mais encadrées. OpenAI a renforcé la chaîne de vérification sur les risques de deepfake et d’influence politique, ce qui produit parfois des faux positifs sur des prompts légitimes.
Ce que cela change pour vous
Si vous produisez régulièrement du contenu visuel avec texte—infographies, mockups, posters, slides, visuels réseaux sociaux avec titre—le passage à ChatGPT Images 2.0 est un gain immédiat, même en mode Instant sur un plan gratuit. Le rendu correct des titres et des labels élimine également le passage systématique par Canva pour ajouter le texte après coup.
Si vous travaillez sur des campagnes multi-formats, des storyboards ou des séries cohérentes de visuels, le mode Thinking justifie à lui seul un plan Plus. Huit visuels cohérents en un appel remplacent plusieurs heures de travail itératif.
Si votre besoin principal est la reproduction pixel-parfaite d’un logo de marque ou la consistance de personnage verrouillée par un grand nombre d’images de référence, gardez en tête que gpt-image-2 reste imparfait sur ces deux cas. Pour tout le reste, le modèle est devenu le choix par défaut.
Conversation orale, traduction temps réel, voix expressives : ce que le mode vocal change vraiment dans un workflow quotidien.